고정 헤더 영역
상세 컨텐츠
본문
사이킷런으로 훈련 세트와 테스트 세트 나누기
사이킷런은 머신러닝 모델을 위한 알고리즘뿐만 아니라 다양한 유틸리티 도구도 제공한다.
대표적인 도구가 train_test_split() 함수이다.
해당 함수는 전달되는 리스트나 배열을 비율에 맞게 훈련세트와 테스트 세트로 나누어 준다
from sklearn.model_selection import train_test_split
train_test_split(arrays, test_size, train_size, random_state, shuffle, stratify)(1) Parameter
arrays : 분할시킬 데이터를 입력 (Python list, Numpy array, Pandas dataframe 등..)
test_size : 테스트 데이터셋의 비율(float)이나 갯수(int) (default = 0.25)
train_size : 학습 데이터셋의 비율(float)이나 갯수(int) (default = test_size의 나머지)
random_state : 데이터 분할시 셔플이 이루어지는데 이를 위한 시드값 (int나 RandomState로 입력)
shuffle : 셔플여부설정 (default = True)
stratify : 지정한 Data의 비율을 유지한다. 예를 들어, Label Set인 Y가 25%의 0과 75%의 1로 이루어진 Binary Set일 때, stratify=Y로 설정하면 나누어진 데이터셋들도 0과 1을 각각 25%, 75%로 유지한 채 분할된다.
(2) Return
X_train, X_test, Y_train, Y_test : arrays에 데이터와 레이블을 둘 다 넣었을 경우의 반환이며, 데이터와 레이블의 순서쌍은 유지된다.
X_train, X_test : arrays에 레이블 없이 데이터만 넣었을 경우의 반환
[출처] [Python] sklearn의 train_test_split() 사용법|작성자 Paris Lee
How Deep is the Learning : 네이버 블로그
- Deep Learning - Computer Vision - Medical Imaging - Backend - Daily
blog.naver.com
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target
= train_test_split(fish_data, fish_target,stratify=fish_target , random_state = 42)random_state로 랜덤 시드를 지정해주고 stratify 매개변수를 통해 타깃 데이터를 전달하면 클래스 비율에 맞게 데이터를 나눈다
수상한 도미 한마리
이제 데이터로 k-최근접 이웃을 훈련해보고 길이가 25고 150인 도미를 테스트해보자!
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)
print(kn.predict([[25, 150]])) # [0.]도미 데이터를 넘겼는데 0이라고 뜬다!!!!!!!!!
이를 산점도로 표현해보면 다음과 같다.

분명 이 데이터는 도미쪽에 가깝다 근데 왜 빙어라고 판단한 걸까?
k-최근접 이웃은 주변의 샘플 중에서 다수인 클래스를 예측으로 사용한다. KNeightborsClassfier 클래스는 주어진 샘플에서 가장 가까운 이웃을 찾아 주는 kneighbors()메서드를 제공한다. 이 메서드는 이웃까지의 거리와 이웃 샘플의 인덱스를 반환한다.
이를 그려보자
distances, indexes = kn.kneighbors([[25,150]])
plt.scatter(train_input[:,0], train_input[:,1])
plt.scatter(25,150, marker = "^")
plt.scatter(train_input[indexes, 0], train_input[indexes,1], marker="D")
plt.show()
가장 가까운 생선들 중 무려 4개가 빙어다!!!!!! 그래서 우리의 모델은 해당 데이터를 빙어라고 판단한 것!
해당 점에서 인접 5개의 점까지의 거리는 다음과 같다.
print(distances)
#[[ 92.00086956 130.48375378 130.73859415 138.32150953 138.39320793]]
데이터 전처리
데이터를 표현하는 기준이 다르면 알고리즘이 올바르게 예측할 수 없다.
이런 알고리즘들은 샘플 간의 거리에 영향을 많이 받으므로 제대로 사용하려면 특성값을 일정한 기준으로 맞추어야 한다
이런 작업을 데이터 전처리 라고 한다
표준점수 이용하기
가장 널리 사용하는 전처리 방법 중 하나이다.
데이터에서 평균을 빼고 표준 편차로 나누어 보자!
mean = np.mean(train_input, axis = 0)
std = np.std(train_input, axis=0)
train_scaled = (train_input-mean)/std
plt.scatter(train_scaled[:,0], train_scaled[:,1])
new = ([25,250]-mean)/std
plt.scatter(new[0],new[1], marker = "^")
plt.show()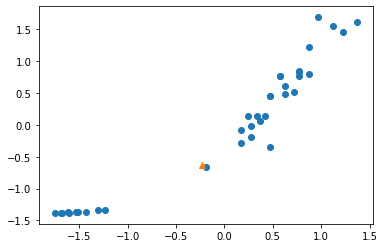
표준편차로 변화하기 전의 산점도와 거의 비슷하지만
이 전과 다르게 x축과 y축의 범위가 바뀐 것을 볼 수 있다.
이제 훈련해보자!
kn.fit(train_scaled, train_target)
테스트해보면
kn.score(test_scaled, test_target)
# 1.0잘 예측 되는 것을 알 수 있다.
그럼 이제 그 이상한 도미를 예측해보자
print(kn.predict([new]))
#[1.]드디어 도미로 예측했다!!
이 데이터를 산점도로 다시 표현해보자
distance, indexes = kn.kneighbors([new])
plt.scatter(train_scaled[:,0], train_scaled[:,1])
plt.scatter(new[0], new[1], marker="^")
plt.scatter(train_scaled[indexes, 0], train_scaled[indexes, 1], marker="D")
plt.show()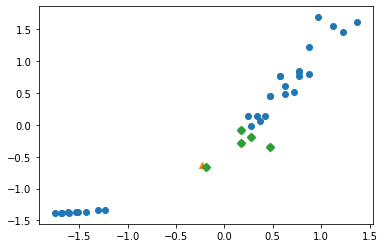
'AI' 카테고리의 다른 글
| [딮러닝 튜토리얼] 섹션 1 - 2. Multilayer Perceptron 소개 (0) | 2023.10.10 |
|---|---|
| [딮러닝 튜토리얼] 섹션 1 - 1.Neural Network 소개 (0) | 2023.10.10 |
| [혼자 공부하는 머신러닝+딮러닝]데이터 다루기 - 훈련 세트와 테스트 세트 (0) | 2023.10.05 |
| 데이터 시각화 - seaborn (2) | 2023.10.05 |
| [Pandas] 판다스 데이터프레임(DataFrame) (0) | 2023.09.20 |




